![]()
![]()
![]()
![]()
![]()
![]()



Τεχνητή νοημοσύνη εναντίον της παιδικής πορνογραφίας στο Ίντερνετ
Δεκέμβριος 03, 2016Τη δυνατότητα αυτόματου εντοπισμού νέων εικόνων και βίντεο παιδικής πορνογραφίας στο Διαδίκτυο παρέχει νέο εργαλείο τεχνητής νοημοσύνης, έμπνευση για το οποίο ήταν οι φωτογραφίες του χεριού ενός μωρού.
Ο έγκαιρος εντοπισμός του νέου υλικού μπορεί να παρέχει στις αρχές τα στοιχεία που χρειάζονται για τον εντοπισμό και τη δίωξη των δραστών, υποστηρίζουν οι ερευνητές που το ανέπτυξαν, σύμφωνα με δημοσίευμα του BBC.
Το συγκεκριμένο σύστημα είναι δωρεάν διαθέσιμο στις υπηρεσίες ασφαλείας και χρησιμοποιείται ήδη από αρκετές ευρωπαϊκές χώρες.
Η σχετική έρευνα πραγματοποιήθηκε στο πλαίσιο του προγράμματος iCOP (identifying and catching originators in peer-to-peer networks), που ιδρύθηκε στο πλαίσιο του προγράμματος της Κομισιόν για ένα ασφαλέστερο Ίντερνετ.
Την έρευνα διεξήγαγαν ερευνητές του Lancaster University, του Γερμανικού Ερευνητικού Κέντρου για την Τεχνητή Νοημοσύνη και του University College Cork στην Ιρλανδία.
Όπως είπε η επικεφαλής ερευνήτρια, Κλόντια Πίρσμαν (Lancaster University), «Όταν άρχιζα ως junior ερευνήτρια με ενδιαφέρονται στην υπολογιστική γλωσσολογία (computational linguistics) είδα μια παρουσίαση από έναν αστυνομικό της Ιντερπόλ που υποστήριζε πως ο ακαδημαϊκός κόσμος θα έπρεπε να επικεντρώνεται περισσότερο στην ανάπτυξη λύσεων για τον εντοπισμό υλικού με κακοποίηση παιδιών online».
«Αν και αναγνώρισε προφανώς ότι υπάρχουν και άλλα εγκλήματα που επίσης αξίζουν προσοχής, σε ένα σημείο είπε “ξέρετε αυτά τα γλυκά χεράκια των μωρών με τις φουσκωμένες αρθρώσεις. Τα βλέπω online κάθε μέρα”. Εκείνη τη στιγμή ήξερα πως ήθελα να κάνω κάτι για να το σταματήσω αυτό».
Το σύστημα αυτό λειτουργεί χρησιμοποιώντας έναν συνδυασμών ανάλυσης ονομάτων αρχείου εντοπίζοντας κλασικά filenames όπως «ch1ld». Αυτά δεν εντοπίζονται βάσει κανονικών αναλυτικών διαδικασιών από υπολογιστές, αν και μπορούν να εντοπιστούν εύκολα από ανθρώπους.
Ωστόσο, ο μεγάλος όγκος του υλικού καθιστά αδύνατο τον εντοπισμό κάθε αρχείου από τους αστυνομικούς.
Το λογισμικό επίσης εντοπίζει το «κωδικοποιημένο» λεξιλόγιο των παιδόφιλων, που χρησιμοποιείται σε σχέση με τις εικόνες, με χρήση λέξεων όπως πχ «Lolita».
Το δεύτερο κομμάτι του συστήματος είναι η ανάλυση εικόνων, με το λογισμικό τεχνητής νοημοσύνης να μπορεί να εντοπίζει εικόνες παιδιών μέσω λεπτομερειών όπως το χρώμα του δέρματος ή εντοπίζοντας κινήσεις που σχετίζονται με σεξουαλική κακοποίηση.
Εκατοντάδες χιλιάδες εικόνες και βίντεο σεξουαλικής κακοποίησης παιδιών διαμοιράζονται κάθε χρόνο.
Υπάρχουν ήδη διάφορα εργαλεία για χρήση από τις αρχές για την παρακολούθηση peer-to-peer δικτύων, αλλά αυτά βασίζονται συνήθως στον εντοπισμό γνωστού υπάρχοντος υλικού.
Όπως τονίζει η Πίρσμαν, ο εντοπισμός νέου υλικού είναι πολύ σημαντικός, καθώς μπορεί να υποδείξει εγκαίρως πρόσφατη, ή συνεχιζόμενη κακοποίηση παιδιών, έτσι ώστε να καταστεί δυνατή η σύλληψη των δραστών.
ΠΗΓΗ: naftemporiki.gr

Όπως είπε, το Facebook θα επιτρέψει σε εμπορικές επιχειρήσεις και εταιρείες να φτιάχνουν προγράμματα αυτόματης επικοινωνίας με τους χρήστες της πλατφόρμας μέσω του Messenger. Τα λεγόμενα «bots» στη γλώσσα των προγραμματιστών (από τη σύντμηση της λέξης ρομπότ) θα απαντούν στα «θέλω» των χρηστών, χρησιμοποιώντας «φυσική γλώσσα».
«Δεν έχω γνωρίσει κανέναν που να του αρέσει να τηλεφωνεί σε μια επιχείρηση. Και κανείς δεν θέλει να πρέπει να εγκαταστήσει μια νέα εφαρμογή για κάθε υπηρεσία ή επιχείρηση με την οποία θέλει να κάνει κάτι», υποστήριξε ο Ζούκερμπεργκ.
Έτσι, πληκτρολογώντας ο χρήστης του Messenger μια λέξη κλειδί εν είδει αναζήτησης, όπως το εμπορικό όνομα κάποιας επιχείρησης, στο ειδικό πεδίο της αναβαθμισμένης εφαρμογής θα ξεκινά ένα chat μέσω του οποίου θα μπορεί να παραγγείλει αυτό που θέλει ή ακόμα και να ζητήσει συγκεκριμένες πληροφορίες και ειδήσεις γύρω από ένα θέμα.

Δεν θα απαιτείται η εγκατάσταση κάποιας επιπλέον εφαρμογής. Ψάχνοντας για παράδειγμα να παραγγείλει λουλούδια, το bot της εκάστοτε επιχείρησης θα του απαντά με τις υπάρχουσες επιλογές και αφού εκείνος επιλέξει το μπουκέτο της αρεσκείας του, θα του ζητά να εισάγει τη διεύθυνση αποστολής τους και ίσως κάποιο προσωποποιημένο μήνυμα που θα τα συνοδεύει. Αντίστοιχα θα μπορεί για παράδειγμα να κλείσει τραπέζι σε εστιατόριο, δωμάτιο σε ξενοδοχείο ή να παραγγείλει φαγητό.
Η πληρωμή για την ώρα θα γίνεται μέσω link το οποίο θα παραπέμπει σε κάποια πλατφόρμα συναλλαγών. Πάντως, στο άμεσο μέλλον, το Facebook αναμένεται να ενεργοποιήσει το δικό του ψηφιακό πορτοφόλι, με το οποίο θα είναι εφικτές τόσο οι πληρωμές μέσω του Messenger, όσο και η μεταφορά χρημάτων μεταξύ των χρηστών (P2P payments).
Εκτός του ανοίγματος του Messenger σε τρίτους, ο Μαρκ Ζούκερμπεργκ αναφέρθηκε για ακόμα μια φορά στις πλατφόρμες εικονικής πραγματικότητας (όπου έχει επενδύσει με την εξαγορά της Oculus) και στη νέα υπηρεσία μετάδοσης βίντεο σε ζωντανή ροή (live), μέσω της οποίας μεταδόθηκε στο Facebook η ομιλία του. Όπως είπε η ζωντανή μετάδοση περιεχομένου είναι μια ταχύτατα ανερχόμενη τάση στα social media, τη στιγμή που ένα drone πετούσε πάνω από το κεφάλι του, μεταδίδοντας live βίντεο από τον χώρο του συνεδρίου.
![Facebook: Η τεχνητή νοημοσύνη βοηθά τους τυφλούς να “δουν” τις φωτογραφίες [βίντεο]](/media/k2/items/cache/18268b3298868589c198588806aa7356_Generic.jpg)
Facebook: Η τεχνητή νοημοσύνη βοηθά τους τυφλούς να “δουν” τις φωτογραφίες [βίντεο]
Απρίλιος 05, 2016Σε μια προσπάθεια να βοηθήσει τους χρήστες με προβλήματα όρασης να καταλαβαίνουν τι απεικονίζει μια φωτογραφία, η ομάδα του Facebook αποφάσισε να εκμεταλλευτεί το δίκτυο τεχνητής νοημοσύνης για να προσφέρει αυτόματες περιγραφές κάτω από τις φωτογραφίες του κοινωνικού δικτύου.
Το δίκτυο τεχνητής νοημοσύνης — χαρακτηρίζεται ως “αυτόματο εναλλακτικό κείμενο” — επεξεργάζεται δισεκατομμύρια παραμέτρους και εκατομμύρια φωτογραφίες-παραδείγματα για να αναγνωρίσει τα αντικείμενα που απεικονίζονται σε μια φωτογραφία και η ακρίβεια του ξεπερνά το 80%. Για την ακρίβεια, δεν “βλέπει” τα αντικείμενα, αλλά τα συγκρίνει με αυτή την τεράστια βάση παρόμοιων φωτογραφιών και πραγματοποιεί μια μαντεψιά με μεγάλες πιθανότητες επιβεβαίωσης. Ο μεγάλος στόχος είναι να αντιληφθεί (η τεχνητή νοημοσύνη) τι είναι πιο σημαντικό στην εκάστοτε φωτογραφία.

Όταν αναγνωριστούν τα αντικείμενα και οι άνθρωποι, το λογισμικό δημιουργεί αυτόματα μια περιγραφή για την φωτογραφία, η οποία μπορεί να ξεκινά με τη φράση “η εικόνα μπορεί να περιλαμβάνει” σε περίπτωση που το ποσοστό βεβαιότητας δεν ξεπερνά το 80%. Βέβαια, όπως σε κάθε νευρωνικό δίκτυο, το σύστημα γίνεται ολοένα και καλύτερο όσο αυξάνεται ο όγκος των επεξεργασμένων φωτογραφιών.
Η λειτουργία είναι ενεργή για την εφαρμογή του Facebook για συσκευές iOS σε ορισμένες χώρε (ΗΠΑ, Μεγάλη Βρετανία, Καναδάς, Αυστραλία και Νέα Ζηλανδία), αρκεί η γλώσσα του χρήστη να είναι ρυθμισμένη στα Αγγλικά. Στο κοντινό μέλλον θα προστεθούν περισσότερες γλώσσες, χώρες και πλατφόρμες.
Μηχάνημα τεχνητής νοημοσύνης στη μάχη κατά του καρκίνου
Φεβρουάριος 22, 2016Ένα μηχάνημα με τεχνητή νοημοσύνη μπορεί ίσως να ανακαλύψει κρυφές μέχρι σήμερα σχέσεις ανάμεσα σε περιστατικά καρκίνου, οι οποίες έχουν ξεφύγει από τους γιατρούς.
Αυτή ακριβώς είναι η ιδέα που για πρώτη φορά έχουν βάλει σε εφαρμογή ερευνητές του Αντικαρκινικού Κέντρου Memorial Sloan Kettering της Νέας Υόρκης, οι οποίοι τροφοδοτούν ένα νέο πρόγραμμα τεχνητής νοημοσύνης με εκατοντάδες χιλιάδες κλινικές σημειώσεις και άλλα στοιχεία πάνω σε πραγματικά περιστατικά ασθενών (συμπτώματα, αιμοληψίες, βιοψίες, «κοκτέιλ» χημειοθεραπειών, παρατηρήσεις γιατρών κ.α.).
Το πρόγραμμα εκπαιδεύεται σταδιακά να διαβάζει αυτόν τον τεράστιο όγκο ιατρικών δεδομένων και να προσπαθεί να βρει ομοιότητες ανάμεσα σε περιστατικά, που εκ πρώτης όψεως φαίνονται άσχετα μεταξύ τους.
«Ψάχνουμε μέσα σε όλα αυτά τα δεδομένα, μήπως βρούμε κάτι ενδιαφέρον», δήλωσε ο επικεφαλής της έρευνας Γκούναρ Ρετς, ο οποίος έκανε τη σχετική ανακοίνωση στο ετήσιο συνέδριο της Αμερικανικής Ένωσης για την Προώθηση της Επιστήμης (AAAS) στην Ουάσιγκτον την προηγούμενη εβδομάδα, σύμφωνα με το New Scientist.
Στόχος των ερευνητών είναι να αναπτύξουν υπολογιστικά μοντέλα, που θα αναλύουν την πορεία της ασθένειας κάθε ασθενούς, τη σχέση της πάθησής του με άλλους ασθενείς και την πιθανή εξέλιξή της στο μέλλον. «Αν έχουμε κάτι τέτοιο στη διάθεσή μας, θα μπορούμε να εξετάσουμε με ποιό τρόπο θα θεραπεύσουμε καλύτερα τον συγκεκριμένο ασθενή», ανέφερε ο Ρετς.
Μέχρι στιγμής, ο αλγόριθμος των ερευνητών έχει διαβάσει ανώνυμες ιατρικές σημειώσεις και άλλα δεδομένα για περίπου 200.000 καρκινοπαθείς. Οι γιατροί, μεταξύ άλλων, ελπίζουν να φέρουν στο φως περιπτώσεις καρκίνου με κοινό γενετικό υπόβαθρο, «ποντάροντας» στο ότι -παρά την άγνοια ασθενών και γιατρών- η μηχανή τεχνητής νοημοσύνης θα διακρίνει κρυφές ομοιότητες στα ιατρικά ιστορικά.
Παράλληλα, άλλα προγράμματα τεχνητής νοημοσύνης εκπαιδεύονται να κάνουν ιατρικές διαγνώσεις, μετά από αξιολόγηση ακτινογραφιών, μαγνητικών τομογραφών και άλλων εξετάσεων. Όπως τόνισε ο Ρετς, «ο ανθρώπινος νους -και του γιατρού- είναι περιορισμένος, συνεπώς προκύπτει η ανάγκη να χρησιμοποιήσουμε τη στατιστική και την επιστήμη των υπολογιστών».
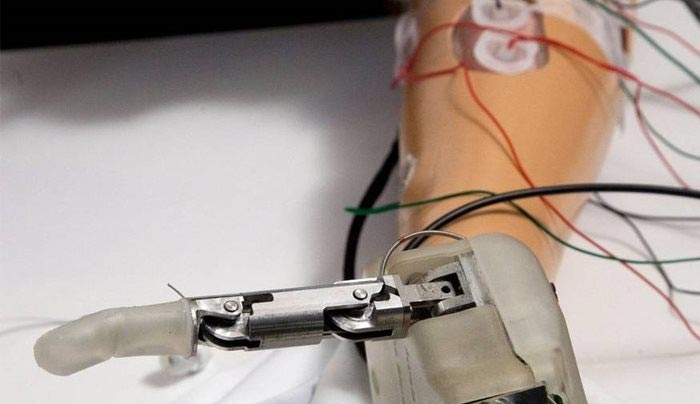
Πρωτοφανές! Ασθενής ελέγχει με το νου τον προσθετικό βραχίονά του
Φεβρουάριος 17, 2016Αν και η έρευνα βρίσκεται ακόμη σε αρχικό στάδιο, θα βοηθήσει τους ανθρώπους που έχουν χάσει τα χέρια τους λόγω τραυματισμού ή ασθένειας, να αποκτήσουν ξανά κάποιες δυνατότητες κίνησης.
Ο ρομποτικός βραχίονας αναπτύχθηκε από γιατρούς και μηχανικούς της Ιατρικής Σχολής και του Εργαστηρίου Εφαρμοσμένης Φυσικής του Πανεπιστημίου Τζονς Χόπκινς των ΗΠΑ, με επικεφαλής τον καθηγητή νευρολογίας Νέιθαν Κρόουν, οι οποίοι έκαναν τη σχετική δημοσίευση στο περιοδικό νευρωνικής μηχανικής "Journal of Neural Engineering".
«Πιστεύουμε πως είναι η πρώτη φορά που ένας άνθρωπος, χρησιμοποιώντας μια ελεγχόμενη από το νου προσθετική συσκευή, κίνησε αμέσως τα δάχτυλά του ανεξάρτητα το καθένα από τα άλλα. Πρόκειται για βήμα εξέλιξης σε σχέση με τα υπάρχοντα προσθετικά άκρα, στα οποία τα τεχνητά δάχτυλα κινούνται όλα μαζί ως μια ενιαία μονάδα, για να πιάσουν κάτι».
Η ακρίβεια των κινήσεων των τεχνητών δαχτύλων με το νέο προσθετικό άκρο φθάνει το 88% περίπου. Η συσκευή είναι εύκολη στη χρήση, αλλά η σχετική τεχνολογία απέχει ακόμη χρόνια από την κλινική εφαρμογή της, ενώ αναμένεται να είναι ακριβή.
Ροή Ειδήσεων







Ελλάδα




Δωδεκάνησα


Οικονομία













